How Does RAG Work? Explained by AI Experts (2026 Guide)

Have you ever wondered, if the generative AI solutions are trained on a predefined dataset, how do they provide the right answers to some of the events that have happened recently? If you ask ChatGPT about the cricket match result that happened last week only, you will still get the right answer. It doesn’t mean that the AI model is being retrained now and then but it’s how RAG works. RAG is simply the technology that connects AI tools to external data sources and helps them gather the latest information according to the user’s prompt.
In this article, we will talk everything about what is RAG AI, why it is important for new solutions, what role it plays, how does RAG works, and everything that you can think about.
What is Rag in AI?
RAG refers to the Retrieval-Augmented Generation. This is the technological architecture that helps artificial intelligence models and solutions connect to external knowledge sources and databases to gather information. Thus, it becomes easier for AI solutions to provide better, more efficient, and more accurate responses. You must know that all the generative AI models and applications are trained on a pre-defined dataset. So, the answers that we receive from these models can be finite and might fail to give us insight into the latest trends and incidents.
For example, if the election results were announced last week, the limited dataset might not be efficient in providing the name of the newly elected candidate. Thus, the RAG architecture helps the AI model to gather real-time information from external sources and thus provide the relevant information. The external data sources may include social media content, internet articles, and public domain works. A lot of business developers and AI solution development companies use RAGs to enhance the capabilities of their artificial intelligence-based tools and provide a better user experience.
Understanding the Two Main Components of RAG
There are mainly two components which play the core role in the functioning of RAG technology. The first one is the retrieval engine which is responsible for finding the right information from a range of external sources. The second one is a generation engine that uses the collected information to curate a relevant and accurate response. Here is the complete explanation of components of RAG along with how RAG works with these core components.
1. Retrieval
The retriever is a setup of retrieval augmented generation with the large language model which is responsible for capturing the complex relationship between the query asked by the user and the documents available for faster and more accurate result generation. For example, it fetches that data in a vector space where it assesses the resemblance between a document and the query. If the query and document are somehow relevant, the distance between these two is less in the vector space. Similarly, if the document is irrelevant to the query, the distance between the document and the query is increased so that it doesn’t fetch the information from the irrelevant document. All this dense embedding is stored in the vector space of the retrieval component.
This process is continued multiple times till the retrieval finds the right document to get the answer to the query. As soon as the right document is fetched in the vector space, it is forwarded to the generator. The number of documents being forwarded is highly dependent on the type of query asked by the user. For example, if the user wants a deep understanding of a topic, the broad set of documents is forwarded to the generator and vice versa.
The most important part of the retrieval engine is the fetch the right document and give the right distance to the query in the vector space. There is a threshold distance, and the document falling behind this threshold distance is not qualified for use. So, it becomes necessary that threshold distance aligns with the objective so that it can help to collect the required information.
2. Generation
Generator engine is the next important component of RAG architecture which is also similar to a large transformer model. It resembles to those GPT 3.5, GPT4, PaLM, BERT, Llama2, and more. In the retrieval generation process, this engine is responsible for taking the query and the forwarded documents from the retrieval engine to generate an accurate and insightful response.
As a part of the process, the document and query are fed into the generator engine which collects the additional texts from the retrieved document, aligns them to the context, and produces a response while eliminating hallucinations.
However, the generator engines used in the RAGs model are different from those of traditional LLMs. For example, the generator engine can create a diverse category of content including texts, videos, and images. On the other hand, the traditional large language models are only capable of generating human-like texts according to the commands provided by the user.
How Does RAG Works: Step-by-Step

RAG pipeline generally consists of 5 simple steps that complete the working mechanism. Go through the below-defined phases and you will have a complete idea about how RAG works.
1. Data Indexing
Data indexing is the first step of the RAG process that refers to the efficient optimization of information so that it can be easily fetched and used in future stages. It simply refers to the process of organizing the books in the library so that any book can be efficiently retrieved when needed. Data indexing helps the RAG model fetch the information that is not available in its language model. There are three types of strategies that are used in the RAG process for efficient data indexing-
- Search Indexing – this is the indexing technique that only indexes the data when it contains the exact matching words. For example, if you have searched for New York, it will only index the document that contains the exact work and not the place, city, USA, etc.
- Vector Indexing – This is a comparatively slower indexing technique that indexes the data based on the meaning of words or phrases. For example, if you are searching for New York, it will also be indexing the documents which contain the words like “city in USA” or “place in USA”.
- Hybrid Indexing – The indexing technique that combines both search indexing and vector indexing is called hybrid indexing. This is one of the best techniques that can improve the diversity and accuracy of data retrieval.
2. Input Query Processing
This is the second step for the RAG working mechanism. The core focus of this phase is to fine-tune the query for its better compatibility with the indexed documents. In this process, the query is simplified and thus removes the irrelevant and unnecessary words from the query. For example, if you are searching for “What is the meaning of RAG?”, it will remove words like is, the, and of, while focusing more on words like what, meaning, and RAG. There are different strategies that are deployed for the processing of queries for multiple types of indexing-
- For search indexing, the input query processing is simple as it focuses on removing the words as defined already. For example, it will generate the query “What meaning RAG?”.
- Vector indexing uses neural network techniques like encoding. Thus, it will generate a query that is also similar to meaning (like definition, and explanation) and RAG (indexing data that also carry AI, full form of RAG, etc.).
- Hybrid indexing uses both exact matches as well as numerical vectors. The combination thus makes the query more concise and output can be obtained easily.
3. Search and Ranking
Once the query has been processed, the RAG focuses on searching for the relevant data in the dataset and thus ranking them according to their relevance with the query. You can better understand it by selecting the books that might contain the answer to your question (if you are not able to get the exact book that you were looking for). Thus a list of data is obtained which might provide the answer to the query. This practice helps the RAG model to get the best information to generate text. There are different algorithms that are used by RAG to generate a response that is useful the the user. The algorithm is chosen according to the indexing technique.
- Algorithm for Search Indexing – TF-IDF (Term Frequency-Inverse Document Frequency) is the first algorithm that is used that rank the documents based on the frequency of query that occurs in the document. BM25 is another algorithm that analyze both the frequency and the longevity of a document to finalize the ranking.
- Algorithm for Vector Indexing – Word Embeddings (e.g., Word2Vec, GloVe) is the algorithm that converts the works into dense vectors to understand the context and relationship between words and queries. Cosine Similarity is another algorithm that can be used. It measures the cosine of the angle between the two vectors. BERT or Transformer models are also used that helps to interpret the intent of the query along with the contextual meanings.
- Algorithm for Hybrid Indexing – The algorithms used in both of the previous indexing methods are used for this hybrid indexing.
4. Prompt Augmentation
As the name suggests, when the right information and documents have been fetched from external sources, the fourth process is dedicated to adding the relevant information to the prompt. Thus, the LLM model can better understand the prompt to provide a more relevant response to the query.
When the prompt is optimized, it becomes easier for the large language model to fetch the keywords from the user’s command. So, the model can now include the related information and insights into the to-be-generated response.
This step is carried out only to ensure that the AI model is not limited to the response to the existing database only but customizing the response according to the users’ expectations.
5. Response Generation
This is the final step of the working mechanism of RAG models. The large language model now deeply analyzes the optimized query, thus creating a tailored response. By deploying the language knowledge, the LLM model now has a prompt that carries the keywords and relevant information. So, an answer is curated based on users’ queries and now contains the most relevant information gathered in real time.
Benefits of RAG Over Traditional LLMs
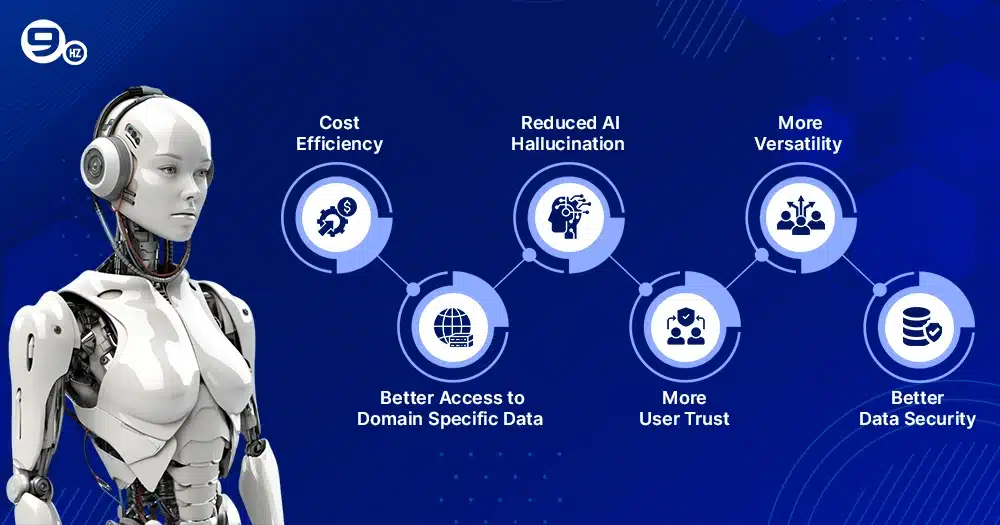
Now that we have discussed how RAG works, it is also important to understand the benefits that it provides the businesses and target audiences. Let have a dive into the advantages that we can leverage using the AI tools that deploys RAG model in generating the response.
1. Cost Efficiency
When businesses plan to implement AI model into their operations, they have to select the foundation model which is trained on a dataset. The dataset includes the information from the existing knowledge available on the search engines, internal documents, etc. However, if the business aims at getting the latest insights on the topic, they only have the option of retraining the data on the new information.
The process of model retraining is very expensive and time-consuming. So, RAG helps businesses get the latest information from their existing model without the need for retraining. With its capability of fetching data from real-time internet sources, it mitigates the need and cost of businesses to retrain the AI model.
2. Better Access to Domain Specific Data
It is a well-known fact that AI models like generative AI have only access to the data that has been used to train them. So, as the generative AI model gets old, the knowledge gap increases and it might fail to provide accurate and real-time information to the user according to the provided prompt. The integration of the RAG model in this situation, helps the generative AI application to fetch the data from external sources and incorporate the real-time information in the response.
3. Reduced AI Hallucination
The working mechanism of the generative AI model only focuses on identifying the patterns in the prompt and thus providing the response according to the pattern. However, the pattern might be biased or inaccurate at times which might cause the hallucination. So, the RAG model helps support the LLM solution to gather more relevant information from the current data and eliminate the chances of AI hallucination.
4. More User Trust
There is no doubt that when an AI model provides a response tailored to the specific query, it will become more reliable to the users. The updated information is more trustworthy to the users. At the same time, the RAG models also have the capability to quote the source of information that allows the users to directly access the relevant and accurate source for providing the reference in their real-life application.
5. More Versatility
When the AI model is capable of extracting real-time information from internet sources, the types of prompts that users can provide to generate the response also increase. So, the versatility of the AI solution is significantly enhanced. As the reliability of the users increases on the AI model, the use cases also increase.
6. Better Data Security
The RAG model only retrieves the data from the active internet sources but doesn’t feed them to the database. So, there is always a distance between the online information and the model. So, it becomes easier for enterprises and businesses to preserve their first-party knowledge while leveraging the RAG models to extract real-time information without compromising or sharing their confidential information with the bots.
Real-World Use Cases of RAG
The increasing reliance of businesses and users has generated a lot of use cases of RAG models in day-to-day life. While sometimes it complements the existing AI model, other times it is helping the research and content generation. Here are the core use cases associated with how does RAG works-
1. Specialized Chatbots
With a significant upgrade from the traditional chatbot, RAG use cases have been expanded to produce specialized chatbots that can offer an enhanced user and customer experience. Whether it is providing the latest updates on the new product or service provided by the company or any change in the rules or regulations of the organization, the specialized chatbot covers it all. Similarly, it can analyze the previous transactions and personal preferences of the users to generate better responses.
2. Research
Generative AI was never an ideal tool that could be used for the research. The reason is simple. If you are relying on a tool that has limited knowledge of a topic and has a significant chance of providing outdated or biased information, you are just doing the damage to your research. However, the evolution of the RAG model has changed the concept completely. With this mechanism, the user can now rely on the AI model for their research as the RAG model also provides the reference sources while providing real-time information on a query.
3. Content Generation
The content generation from generative AI is entirely different as compared to content generated from the RAG model. The latter has the capability of including the latest statistics and information about the topic. At the same time, it can also provide authoritative sources of information for the increased reliability of the content.
4. Market and Product Analysis
It becomes much easier with the implementation of the RAG model. For example, the product owner can easily assess the reviews shared by the users on social media channels, websites, and eCommerce platforms. At the same time, the AI model can also extract insightful and actionable information from the collected information to make it easier for the product owner to take the required actions for making the required improvements in the product.
5. HR Assistance
With the implementation of the RAG model, the need for manual assistance in the human resource management of the company can be eliminated. For example, the updates on the salary invoice, HR support, onboarding process, interview updates, and much more can be accessed with the help of RAG integrated AI model.
6. Recommendation Engine
RAG-powered AI model performs the role of a recommendation engine for a brand that connects to it consistently and helps them choose the best product according to their personalized needs. For example, the RAG model can provide insights into the newly launched product, and the response from the customer, and also suggest if the particular product has the features of meeting the users’ requirements.
Challenges and Limitations
Sometimes we also have to face some challenges when going for something good that can help transform our operational processes. Similarly, the implementation of RAG technology is also associated with some challenges and limitations. Let’s understand how RAG works with all these challenges-
- First of all, it is important that the RAG model is fetching the data from the right source. If the data source of RAG is not accurate, the response will also be not satisfactory.
- There are different data formats like graphs, images, and slides which RAG can not read in real-time. So, even if the relevant insights are available on the online data sources, the RAG model might not fetch and use them.
- The RAG model only identifies the relevant data and then uses them in responding to the query. So, if the online data is biased, the output is also likely to be biased.
- The issues and challenges like intellectual property, privacy, security, and licensing of data are always associated with the RAG model which has to be refined manually by the user.
- Sometimes, there can be latency issues due to delays between different processes like understanding the query, fetching the data from the external sources, finding the relevant document, preparing the response, and providing the response.
- If the top online sources are not providing the latest updates and news on a topic, there are chances that the RAG model as well, might not be able to fetch the information.
Tools and Frameworks for Building RAG Systems
Multiple tools and frameworks can be used to build an RAG system. Each of them has their core competencies which bring the ultimate purpose of RAG to life. Here are some of the best tools and frameworks that are used to develop RAG systems-
1. LangChain
LangChain has been existing in the market even when people have not heard anything about RAG. Thus, it makes the LangChain one of the most preferred frameworks for developers to build RAG models.
LangChain simplifies the building process of the RAG application by providing the modular abstraction of many important and basic components including vector store, document loader, embeddings, and LLM interactions. At the same time, it also helps in the easy swapping of different components. The integration of the LangChain framework enables the developers to focus more on the application logic by streamlining the development process.
2. LlamaIndex
The core competency of LlamaIndex is that it allows the developers to connect their own data sources to the RAG system for better and verified responses. Thus, the RAG model developed by using the LlamaIndex framework is more adaptable and versatile in real-life applications.
LlamaIndex follows the 5 steps to define how RAG works. The first one is data ingestion, the second is document processing, the third is index construction, the fourth is response generation, and the last one is query processing. This working mechanism allows the efficient integration of both structured and unstructured data sources and thus increasing the use case of RAG model.
3. Haystack
Haystack is an open-source framework that provides a comprehensive set of tools and simplifies the overall development process of the RAG model. The tools are responsible for managing the retrieval of information from documents, and thus also foster the seamless integration of data into a large language model for a more relevant response. Tasks like fine-tuning of retrieval process, data management, and seamless integration with different LLMs become easier with the use of the Haystack framework.
How does RAG Improve AI Search and Chat?
RAG is undoubtedly the key to better search results and increased reliability on the AI models for different tasks. There are different core competencies of RAG models that help to improve the AI search and chat experience of users with the AI models.
- RAG provides access to fresh information which eliminates or at least reduces the chances of inaccurate responses.
- The working mechanism of RAG focuses on prioritizing the documents that talk best about the provided topic. Thus, the chances of a detailed understanding of the topic increases.
- With RAG, identifying the source of data is very easy, and thus, researchers can rely on the AI search for their assignments.
- RAG eliminates the need to retrain the data manually and thus helps to make the solution scalable and adaptable to the changing business needs.
- RAG model also enhances the chat experience of the user as it analyzes the query and different types of indexing techniques allow the users to get the customized response according to their particular requirements.
- There is always a distance between the enterprise data and online data collection which ensures the safety of confidential data at any cost.
How Can The NineHertz Help You In Building and Implementing RAG?
RAG is a powerful tool that can help your AI tool and business to leverage a lot of benefits and competitive advantage. However, there is no doubt that the development partner you choose plays a significant role in determining how RAG works. For example, efficient development will help you embrace all the features of the RAG model while an inefficient development company might waste your resources and time.
The NineHertz is a leading name as a AI development company. With an experience of 15+ years, we specialize in all the industry 4.0 technologies and help our clients sync their steps with the ever-evolving landscape. Here are some of the core competencies that make us the best RAG development company-
1. Free Consultation
For businesses who are dedicated to the advancements of their business, we offer free consultation sessions. Here, you get to talk with our top industrial and technological experts who help to identify the real-time gaps in your business and the best solution to fill them. At the same time, we also guide you toward the resources and time required for the completion of the project.
2. Experience with Expertise
The NineHertz carries experience with expertise. Whether it is RAG, AI, ML, AR/VR, Blockchain, or Metaverse, we have a team of well-versed experts to integrate the best technologies into the solution. At the same time, our expertise helps us to mitigate the challenges during the project without letting it affect the overall outcome quality.
3. Cost Efficient
As an experienced RAG development company, we are familiar with the key practices that help to save cost without compromising the overall project quality. We aim to make digital advancement affordable and accessible to different types and sizes of businesses.
4. Multiple Hiring Model
The NineHertz offers multiple hiring models for different project needs. Our engagement model makes sure that the client can choose the one that suits their project type and particular requirements. At the same time, our hiring models also ensure that client pays only for their need.
5. Maintenance and Support
We provide ample maintenance and support services to our clients once the RAG model has been deployed on the platform. In this offering, we assess the performance of the final solution for a time, identify the bugs to resolve them, analyze the areas of improvement, provide periodic updates, add new features, and much more.
Conclusion: Why RAG Is the Future of Generative AI
RAG is undoubtedly the future of artificial intelligence as it increases the versatility of the solution and makes the response more reliable to the users. There are different benefits like updated information, reduced need for manual retraining, higher security, quoted research sources, and much more that the users can leverage with their AI model integrated with RAG technology. All these benefits are based on two working components viz. Retrieval and Generation also help to define how RAG works.
If you are also a business owner who relies on AI tools and software to automate the everyday tasks in your operational process, it is important for you to integrate the RAG model as it will help you get the better out of your technological architecture while making the model reliable to you. At the same time, the increased versatility of the solution will help you achieve a better ROI from your AI solution.
Connect with The NineHertz for an in-depth understanding of RAG and how it can fulfill your particular business needs.
FAQs About RAG
What makes RAG different from GPT-4?
Answer- GPT4 is a large language model that helps to analyze the user command to generate relevant texts, images, and visuals. On the other hand, RAG is like a catalyst that is integrated into the GPT4 to increase its capability to fetch real-time information from search engines and external data sources to provide a more optimum and insightful response.
Is RAG only useful for enterprises?
Answer- No, RAG is useful for every business that relies on AI tools and software to automate the work process. RAG helps businesses to leverage real-time data and get better insights on the topic. Also, RAG is very helpful in making the AI implementation even more secure and private as it always maintains a distance between business information and online information.
Can RAG work with any data source?
Answer- Yes, different types of data sources are compatible with the working process of RAG models. It includes APIs, databases, online document repositories, and much more. Different types of data formats can be used by RAG including long-form texts, files, database records, etc.
How much does it cost to build an RAG model?
Answer- The cost of RAG model development is highly variable as it can range from $50,000 to $500,000 and more. The development cost of the RAG model is highly dependent on a range of factors like technological infrastructure, development and engineering team, vector database, LLM inference, data and embedding, maintenance and support, etc.
How much time does it take to build the RAG model?
Answer- The timeline of the RAG development project might range from weeks to months. Similar to the development cost, the RAG model development timeline is also influenced by several factors like data size, model complexity, team size, team expertise, integration requirements with existing systems, hiring models, and much more.
Great Together!
Latest Blogs

How AI Is Used in Manufacturing: 10 Use Cases to Know in 2026
AI use cases in manufacturing have transformed the way this industry operates and evolves. While the traditional approach only resulted…

8 Real-World Use Cases of AI Supply Chain Risk Monitoring We’ve Seen Across Modern Enterprises
Key Takeaways AI supply chain risk monitoring uses real-time data and predictive models to flag disruptions before they escalate into…
How an Agentic AI Supplier Risk Intelligence Platform Detects Collapse 90 Days Before It Disrupts Your Operations?
Key Takeaways Traditional SCRMs are ineffective for modern supply chain enterprises, because they fail to detect risks in time, offer…





