How to Install Python Pandas on Windows and Linux?- (pip & Anaconda)

In this blog, we will explore how can you install Python Pandas in windows and Linux using pip & Anaconda.
What is Pandas in Python?
Pandas is an open-source library that provides high-performance, easy-to-use data structures and data analysis tools for the Python programming language. Panda’s name is derived from the term “panel data”, which refers to multidimensional data sets that include observations over time.
Pandas is particularly well-suited for working with tabular data, such as data from a relational database or a spreadsheet. It also supports more complex data structures, such as hierarchical and time series data.
There are two primary data structures in Pandas: the Series and the DataFrame. A Series is a one-dimensional array-like object that can hold any data type, such as integers, floating point values, strings, or Python objects. A DataFrame is a two-dimensional array that can store data of any type. It is similar to a spreadsheet or a database table. In this blog, we will explore how to install Python Pandas in windows and Linux.
How do Pandas Fit into the Data Science Toolkit?
Pandas is a Python package that provides fast, flexible, and expressive data structures designed to make working with structured (tabular, multidimensional, potentially heterogeneous) and time series data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis/manipulation tool available in any language. It is already well on its way towards this goal.
At the core of pandas is a robust data structure, the DataFrame. DataFrames allow you to store and manipulate tabular data in rows and columns. They are similar to the data frames found in R and Python’s statsmodels package, but they contain a number of unique features that make working with data in Python much more intuitive.
In addition to the DataFrame, pandas also provide utilities for reading and writing data from a variety of sources (including CSV, Excel, JSON, SQL, and HTML), as well as working with time series data. You might be interested to know about top python web development companies.
What are the Benefits of Using Pandas?
There are many reasons to use pandas for data analysis. Here are some of the most important:
Pandas is easy to use. The DataFrame structure makes it easy to work with data in rows and columns, and the syntax is close to that of standard Python. This makes pandas easy to learn for new users and reduces the need for extensive code rewriting when transitioning from other data analysis tools.
Pandas is efficient. The library uses optimized algorithms to perform complex operations quickly, and it can handle large amounts of data efficiently.
Pandas is flexible. The DataFrame structure allows you to easily manipulate and transform data, and the built-in methods provide a wide range of statistical and machine learning algorithms.
Certified Python Developers [Hire Now]
Request A Free Quote
What are Some of the Most Important Features of Pandas?
There are many features of pandas that make them an essential tool for data analysis. Some of the most important are:
DataFrames: DataFrames are the core data structure in pandas. They allow you to store and manipulate tabular data in rows and columns.
Series: A Series is a one-dimensional array-like object that can hold any data type (integers, floats, strings, objects, etc.). A Series is similar to a column in a DataFrame, and you can think of it as a special case of a DataFrame with only one column.
Index: The Index is a powerful data structure that allows you to label data (similar to a dictionary). This labeling makes it easy to select and manipulate data.
Reading and Writing Data: pandas provide functions for reading and writing data from a variety of sources (including CSV, Excel, JSON, SQL, and HTML).
Statistical Methods: pandas provide a wide range of statistical methods for data analysis.
Machine Learning: pandas integrates with sci-kit-learn, a powerful machine learning library for Python.
Hardware Requirements to Installing Python Pandas
There are no special hardware requirements for using Pandas.
Operating System Requirements –
Pandas are supported on the following platforms:
- Windows: 32-bit and 64-bit
- Mac OS X: 32-bit and 64-bit
- Linux: 32-bit and 64-bit
Python Version Requirements –
Pandas require Python 2.7 or higher, or Python 3.4 or higher.
How to Install Python Pandas on Windows And Linux?
Installing Pandas on Windows Using pip & Anaconda
Step 1: Search for Anaconda Navigator in Start Menu and open it.
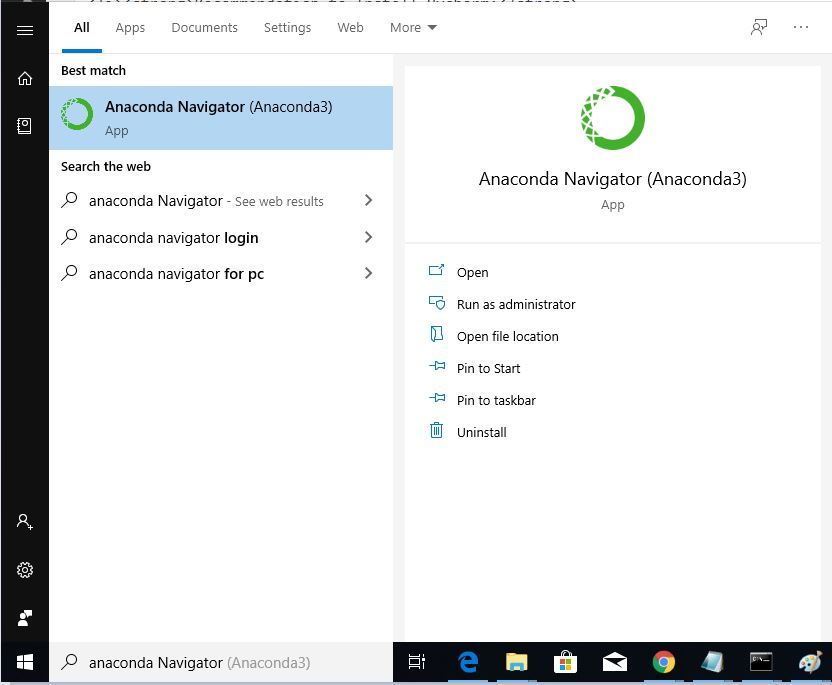
Step 2: In the Anaconda Navigator window, click on the Environments tab.
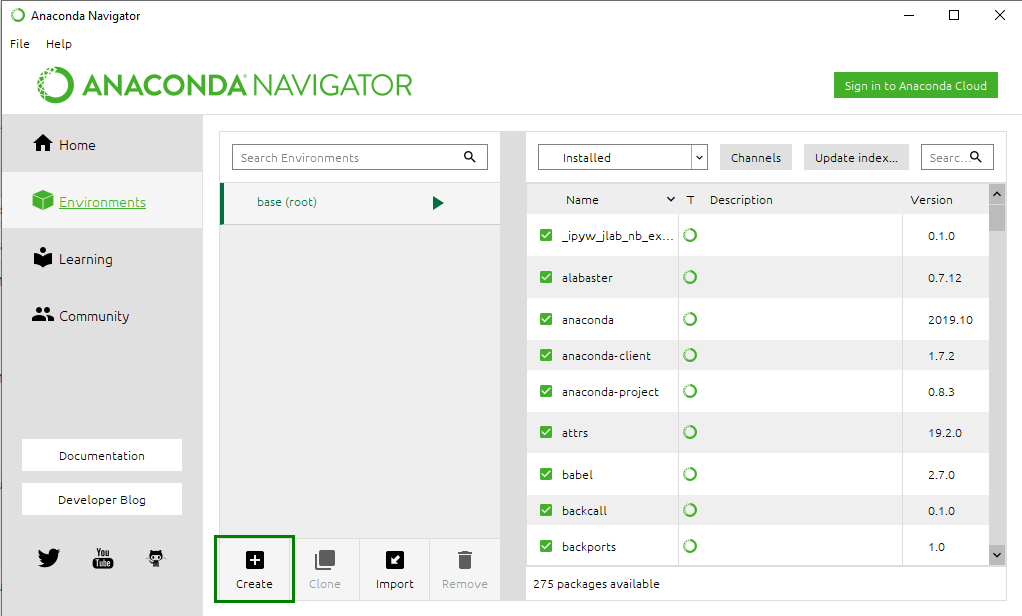
Step 3: Click the Create button.
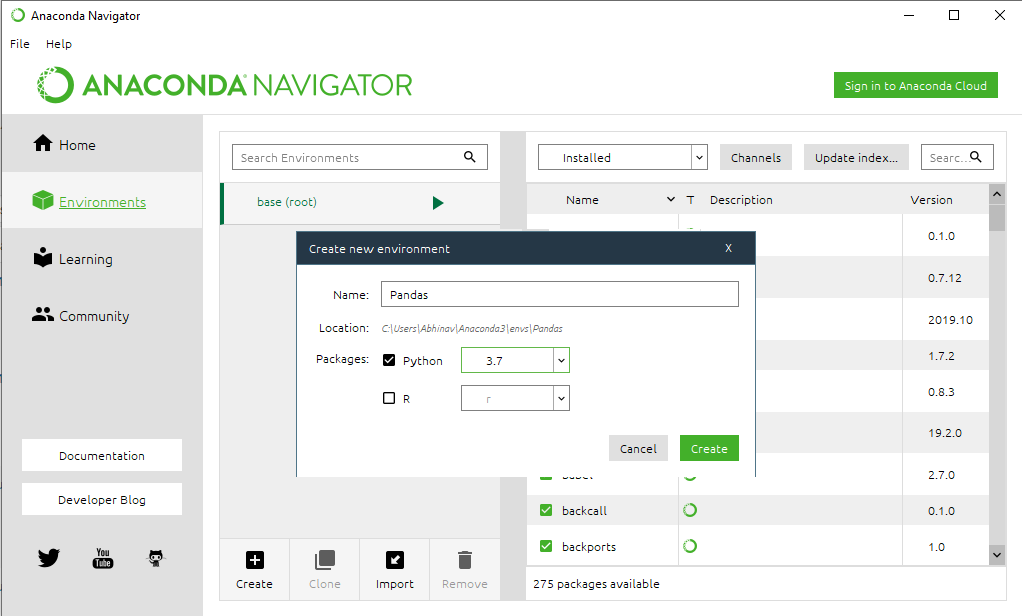
Step 4: In the Create new environment dialog box, specify a name for the new environment in the Environment name field. For example, you can call it “pandas_env”.
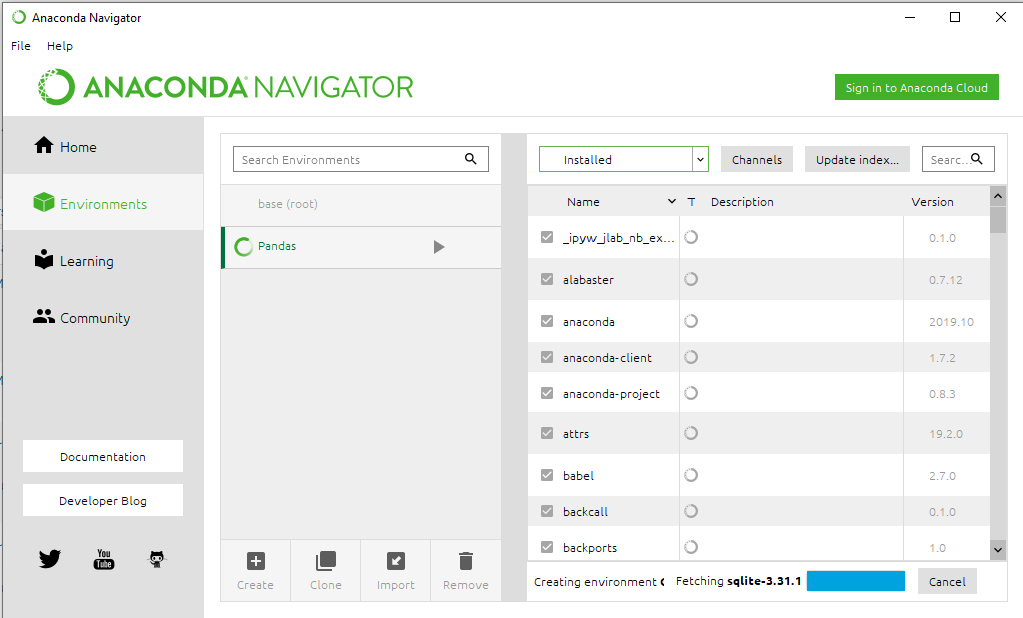
Step 5: Select a Python interpreter from the list of available interpreters. For example, you can choose to use Python 3.6.
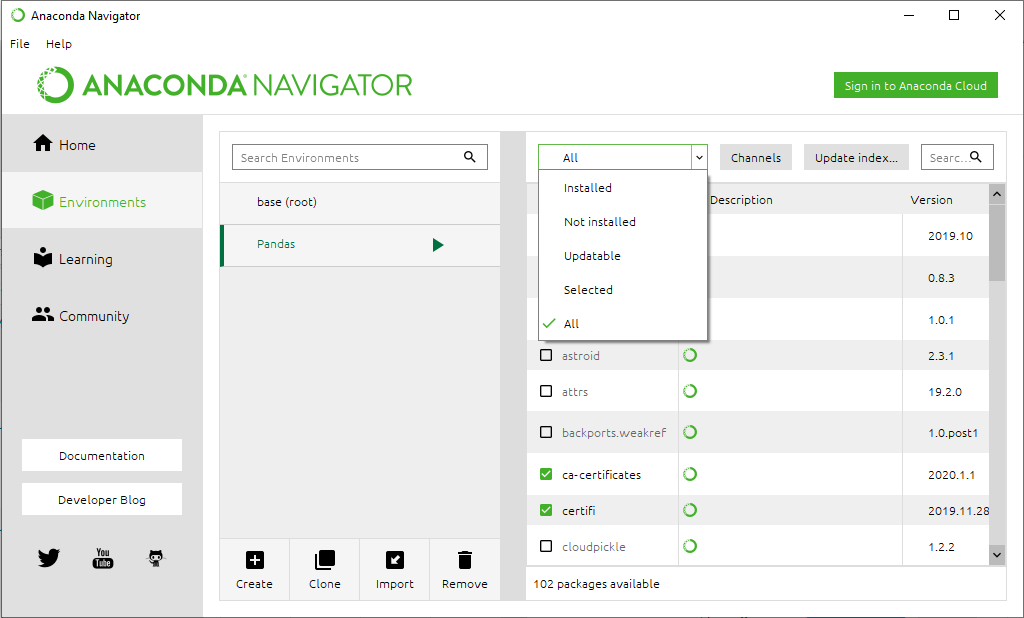
Step 6: Click the Create button.
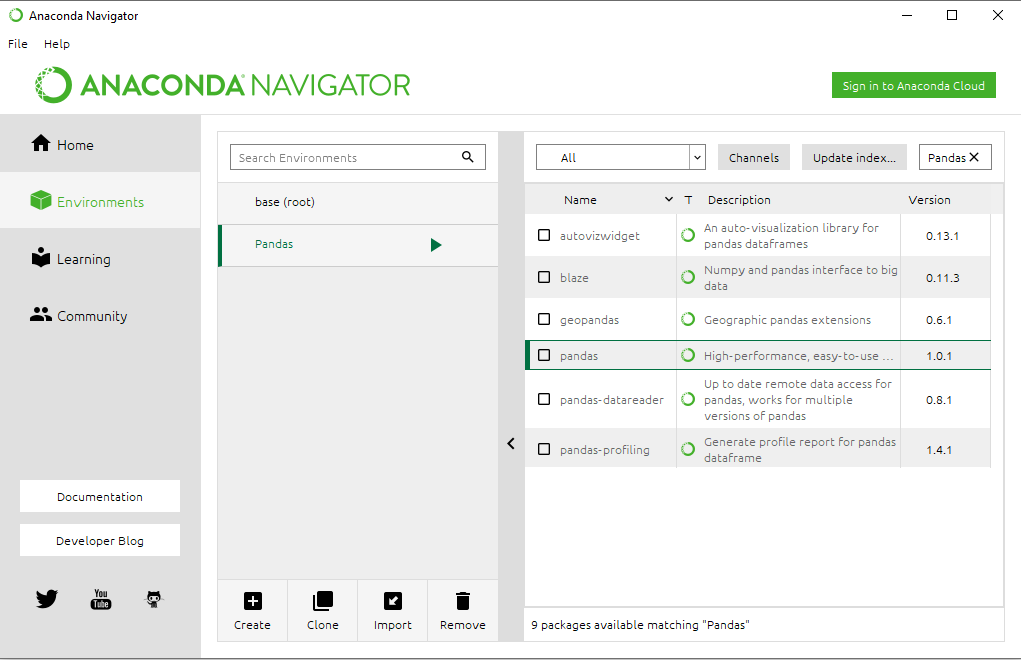
Step 7: After the new environment has been created, you can select it from the list of available environments.
Step 8: Click the Not installed tab.
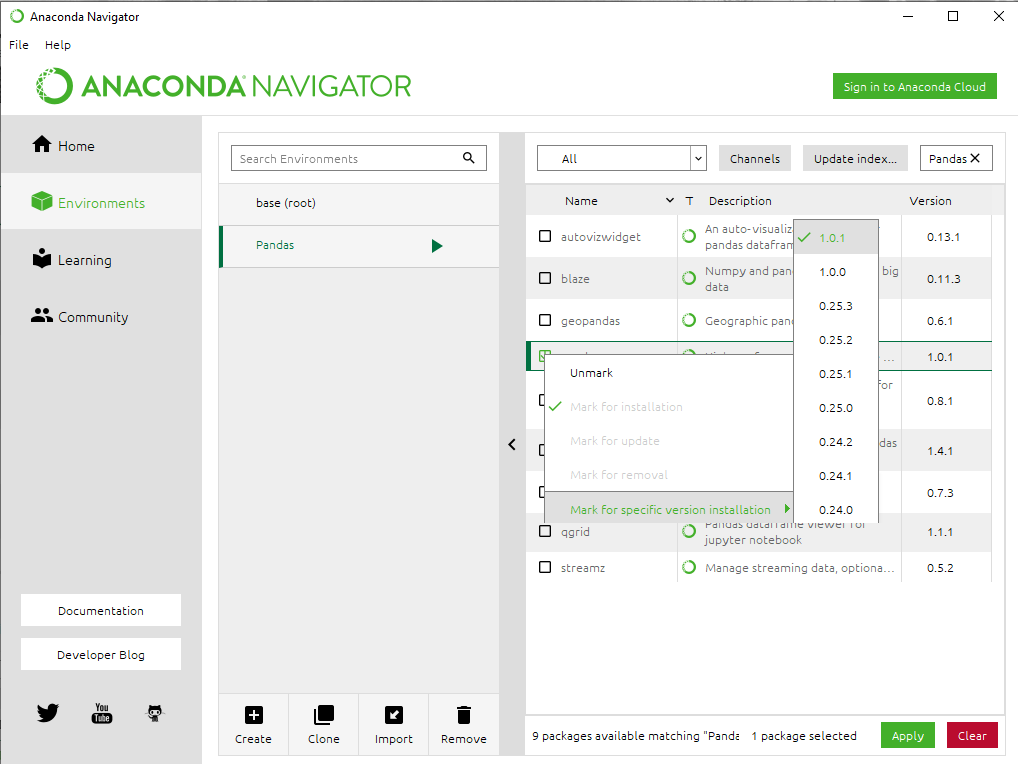
Step 9: In the Search field, type “pandas” and press Enter.
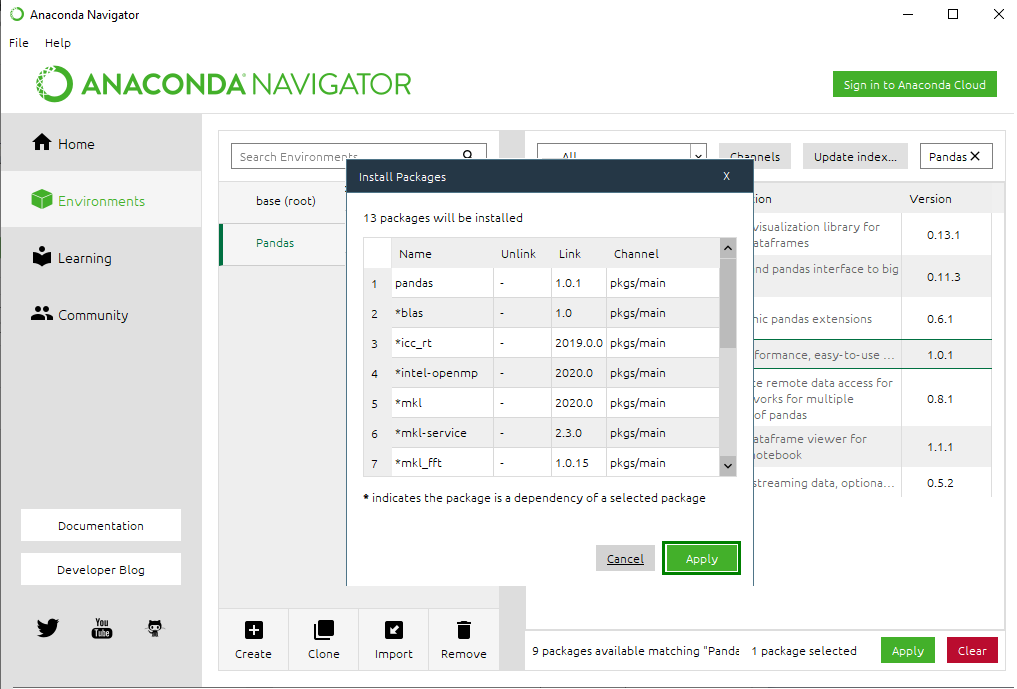
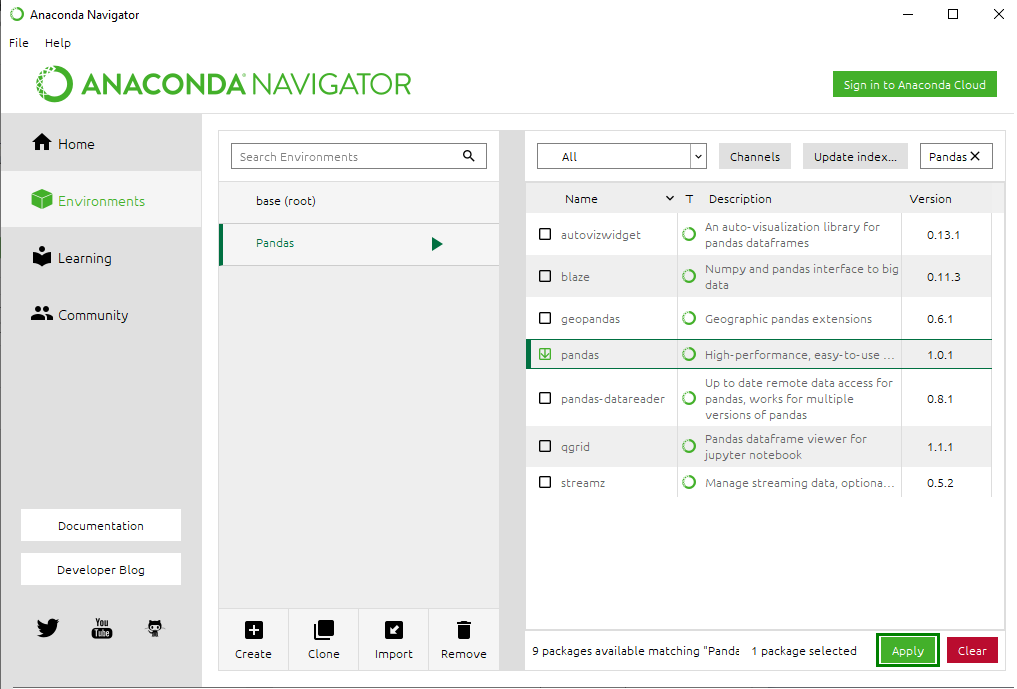
Step 10: Select the checkbox next to the panda’s package and click the Apply button.
Step 11: In the Apply changes to environment dialog box, click the Apply button.
Step 12: Click the Close button.
The pandas package will now be installed in the new environment. You can hire python developers to get help in this.
Installing Pandas on Linux
Step 1: Open a terminal window and enter the following command to install Pandas using pip:
pip install pandas
Step 2: Enter the following command to verify that the installation was successful:
pandas -v
You should see output similar to the following:
pandas 0.23.4
Optional Dependencies
The following packages are optional dependencies that can be used with Pandas:
- NumPy – A fundamental package for scientific computing with Python.
- SciPy – A library of algorithms and mathematical tools for scientific computing.
- matplotlib – A plotting library for Python.
- statsmodels – A statistical modeling and econometrics package.
- pandas-datareader – A package that allows you to load data from various internet sources into a Pandas DataFrame.
- xlrd, openpyxl – Packages that allow you to read and write Excel files.
Great Together!
Latest Blogs

What is Artificial General Intelligence (AGI)?
Artificial Intelligence is a worldwide popular technology that is now revolutionizing the world. It was invented to turn basic computers…
![Everything About WordPress Development – [ A Handy Guide ]](https://theninehertz.com/wp-content/uploads/2020/08/How-Much-Does-WordPress-Development-Cost.jpg)
Everything About WordPress Development – [ A Handy Guide ]
The creation of Matt Mullenweg and Mike Little, WordPress rolled out in 2003. Ever since then, the WordPress Development platform…

Top 15 Generative AI Applications (2026)
Did you know that Generative AI's global market size was valued at nearly $45 billion at the end of 2023?…





